最近一直在做nlp的东西,但都还是了解的太表面了。东西有点多,杂,现在的心情正好适合整理一下。
前言
nlp 自然语言处理,其中又分为很多种类的任务,如机器翻译,情感分析,命名实体识别。之前毕设一直在做事件抽取的东西,但可能是因为做的太浅了,给我的整体感受就是分类任务(其实并不是这么简单),这一次做一个类似命名实体的任务,感觉依旧是一个分类任务。现在,这一系列任务基本可以分为两大步骤,第一就是训练词向量,将无论是英语,中文的语句进行在字符上或者词语上的一个编码,也就是embedding。第二是进行不同网络模型的构建。如何训练好一个词向量限制着所构建的模型能达到的最好效果。
文本的表示
基于one-hot、tf-idf、textrank等的bag-of-words
主题模型:LSA(SVD)、pLSA、LDA
基于词向量的固定表征:word2vec、fastText、glove
基于词向量的动态表征:elmo、GPT、bert
词向量的提取,其实可以类似于一种特征的提取,一般的做法是分词或者是单个字符,进行一个索引抽取。很火的是预训练的方式,即通过一个大的语料库(不需要有标注)进行训练。one-hot是可认为是最为简单的词向量,但存在维度灾难和语义鸿沟等问题。矩阵分解(LSA):利用全局语料特征,但SVD求解计算复杂度大。word2vec、fastText:优化效率高,但是基于局部语料。glove:基于全局预料,结合了LSA和word2vec的优点。为了解决一词多义等问题,引入基于语言模型的动态表征方法:elmo、GPT、bert。
word2vec
word2vec来源于2013年的论文《Efficient Estimation of Word Representation in Vector Space》,它的核心思想是通过词的上下文得到词的向量化表示,有两种方法:CBOW(通过附近词预测中心词)、Skip-gram(通过中心词预测附近的词).
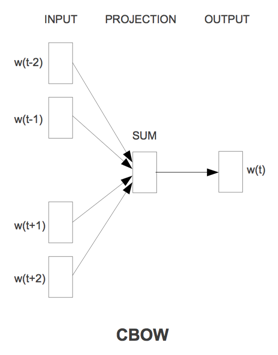
CBOW通过目标词的上下文的词预测目标词
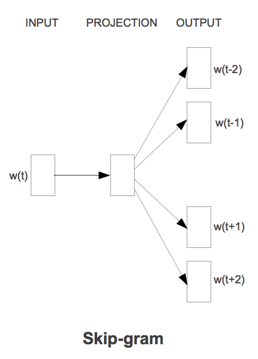
Skip_gram跟CBOW的原理相似,它的输入是目标词,先是将目标词映射为一个隐藏层向量,根据这个向量预测目标词上下文,因为词汇表大和样本不均衡,同样也会采用多层softmax或负采样优化。
如何使用:gensim
gensim支持包括TF-IDF,LSA,LDA,和word2vec在内的多种主题模型算法,
Gensim Word2vec 使用一个句子序列作为其输入,每个句子包含一个单词列表。1
2
3sentences = [['first', 'sentence'], ['second', 'sentence']]
# train word2vec on the two sentences
model = gensim.models.Word2Vec(sentences, min_count=1)
· sentences:可以是一个list,对于大语料集,建议使用BrownCorpus,Text8Corpus或LineSentence构建。
· sg: 用于设置训练算法,默认为0,对应CBOW算法;sg=1则采用skip-gram算法。
· size:是指特征向量的维度,默认为100。大的size需要更多的训练数据,但是效果会更好. 推荐值为几十到几百。
· window:表示当前词与预测词在一个句子中的最大距离是多少
· alpha: 是学习速率
· seed:用于随机数发生器。与初始化词向量有关。
· min_count: 可以对字典做截断. 词频少于min_count次数的单词会被丢弃掉, 默认值为5
· max_vocab_size: 设置词向量构建期间的RAM限制。如果所有独立单词个数超过这个,则就消除掉其中最不频繁的一个。每一千万个单词需要大约1GB的RAM。设置成None则没有限制。
· sample: 高频词汇的随机降采样的配置阈值,默认为1e-3,范围是(0,1e-5)
· workers参数控制训练的并行数。
· hs: 如果为1则会采用hierarchica·softmax。如果设置为0(defau·t),则negative sampling会被使用。
· negative: 如果>0,则会采用negativesamp·ing,用于设置多少个noise words
· cbow_mean: 如果为0,则采用上下文词向量的和,如果为1(defau·t)则采用均值。只有使用CBOW的时候才起作用。
· hashfxn: hash函数来初始化权重。默认使用python的hash函数
· iter: 迭代次数,默认为5
· trim_rule: 用于设置词汇表的整理规则,指定那些单词要留下,哪些要被删除。可以设置为None(min_count会被使用)或者一个接受()并返回RU·E_DISCARD,uti·s.RU·E_KEEP或者uti·s.RU·E_DEFAU·T的函数。
· sorted_vocab: 如果为1(defau·t),则在分配word index 的时候会先对单词基于频率降序排序。
· batch_words:每一批的传递给线程的单词的数量,默认为100001
2
3
4
5
6
7
8# 保存模型
model.save('word2vec.model')
#加载模型
model = gensim.models.Word2Vec.load('word2vec.model')
# 为了方便查看训练的词向量结果,也可以将训练的结果保存为vectors.txt文本文件。
model.wv.save_word2vec_format('vectors.txt', binary=False)
glove
word2vec只考虑到了词的局部信息,没有考虑到词与局部窗口外词的联系,glove利用共现矩阵,同时考虑了局部信息和整体的信息。来自论文《Glove: Global vectors for word representation》。
如何使用:https://nlp.stanford.edu/projects/glove/
简单说一下:
1、下载源码:1
$ git clone http://github.com/stanfordnlp/glove
2、切换到glove目录1
$ cd glove
3、编译1
$ make
4、执行1
$ ./demo.sh
GloVe训练的结果,是可以用gensim里面word2vec的load直接加载并且使用,但是要做一些处理。两者训练出来的文件都以文本格式呈现,区别在于word2vec包含向量的数量及其维度。1
2
3
4
5
6
7
8
9
10
11
12
13
14from gensim.test.utils import datapath, get_tmpfile
from gensim.models
import KeyedVectors
# 输入文件
glove_file = datapath('test_glove.txt')
# 输出文件
tmp_file = get_tmpfile("test_word2vec.txt")
# 开始转换
from gensim.scripts.glove2word2vec import glove2word2vec
glove2word2vec(glove_file, tmp_file)
# 加载转化后的文件
model = KeyedVectors.load_word2vec_format(tmp_file)
对于在keras如何将embedding替换为自己的词向量,https://keras-cn-docs.readthedocs.io/zh_CN/latest/blog/word_embedding/ 介绍得非常清楚
ELMo
ELMo来自于论文《Deep contextualized word representations》,它的官网有开源的工具:https://allennlp.org/elmo
word2vec和glove存在一个问题,词在不同的语境下其实有不同的含义,而这两个模型词在不同语境下的向量表示是相同的,Elmo就是针对这一点进行了优化,作者认为ELMo有两个优势:
1、能够学习到单词用法的复杂特性
2、学习到这些复杂用法在不同上下文的变化
简单来说,ELMO通过双方向预测单词,前向过程中,用1~k-1的词去预测第k个词,后向过程中,用k+1~N的词去预测第k个词。具体的编码方式采用了LSTM
BERT
来自论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》(论文细节可见上篇对BERT译文的翻译)可谓是NLP领域的里程碑。最近一年看过不少相关于BERT的东西了,现在越来越感叹,跟不上节奏了呀…… 在BERT之后已经出来了不少优秀的模型,如百度提出的知识增强的语义表示模型ERNIE
https://github.com/PaddlePaddle/LARK/tree/develop/ERNIE XLNet,
NLP一共有4大类的任务:
序列标注:分词/词性标注/命名实体识别…
分类任务:文本分类/情感分析…
句子关系判断:自然语言推理/深度文本匹配/问答系统…
生成式任务:机器翻译/文本摘要生成…
BERT为这4大类任务的前3个都设计了简单至极的下游接口。
BERT的使用也还算是简单,就是对于机器配置要求较高……(硬伤)可见官方代码:https://github.com/google-research/bert 最近去看发现,又更新了,之前论文中使用的并不是单词全MASK的遮蔽方式,最近更新了一版全字掩蔽,可在create_pretraining_data.py修改–do_whole_word_mask=True使用,官方提供了训练集(只想说太large了啊,一般人跑不动好吗……)
模型的构建
在文本表示之后就是如何构造一个合适的模型去学习了。这个可能得具体例子具体说明。见下篇实战篇——达观杯比赛,信息抽取吧!