不知不觉已经很久不写了……看了看之前的,还真觉得有的知识真是得记下来啊(因为脑子装不下……哈哈哈)回归主题,今天整理了一下nlp最新的BERT模型,涉及太多不懂的了,仍在studying……
前不久,谷歌AI团队新发布的BERT模型,在NLP业内引起巨大反响,被认为是NLP领域里程碑式的进步。BERT模型在机器阅读理解顶级水平测试SQuAD(斯坦福问答数据集)中表现出了惊人的成绩:全部两个衡量指标上全面超越人类,并且还在11种不同NLP测试中创出最佳成绩。接下来和大家分享一下这篇论文.
其实网上也有很多学习笔记(我就是这样看的……)
先丢几个链接:
从Word Embedding到Bert模型——自然语言处理预训练技术发展史
https://mp.weixin.qq.com/s/FHDpx2cYYh9GZsa5nChi4g
GitHub原码
https://github.com/google-research/bert
BERT相关论文、文章和代码资源汇总
http://www.52nlp.cn/tag/bert%E4%BB%A3%E7%A0%81
(看完这里面的也就差不多了……)
论文
https://arxiv.org/abs/1810.04805
BERT论文讲解
https://www.jiqizhixin.com/articles/2018-10-19-19
NLP基本处理流程
https://www.jianshu.com/p/b87e01374a65
主要将分为这几个部分:1、简单的介绍一下BERT以及涉及到的一些东西 2、BERT中的第一项任务MLM,即遮蔽语言模型(masked language model) 3、BERT的第二项任务下一句预测NSP 4、BERT 的应用 5、总结
介绍
BERT模型的全称是Bidirectional Encoder Representations from Transformers,它是一种新型的语言模型。之所以说是一种新型的语言模型,是因为它与其他语言模型相比,有独到之处,这个独到之处在于BERT通过联合调节所有层中的双向Transformer来训练预训练深度双向模型。所以,它只需要一个额外的输出层来对预训练BERT进行微调就可以满足各种任务,没有必要针对特定任务对模型进行修改,这也是为什么BERT模型能做11项NLP任务上取得突破进展的原因。
我觉得几个关键词就是: 双向——>MLM ,Transformer编码,微调
如果你对这些词不了解的话,需要先了解一下。
语言模型
预训练的语言模型对于众多自然语言处理问题起到了重要作用,比如SQuAD问答任务、命名实体识别以及情感识别。
简单地说,语言模型就是用来计算一个句子的概率的模型,即P(W1,W2,…Wk)。利用语言模型,可以确定哪个词序列的可能性更大,或者给定若干个词,可以预测下一个最可能出现的词语。
举个音字转换的例子来说,输入拼音串为nixianzaiganshenme,对应的输出可以有多种形式,如你现在干什么、你西安再赶什么、等等,那么到底哪个才是正确的转换结果呢,利用语言模型,我们知道前者的概率大于后者,因此转换成前者在多数情况下比较合理。
再举一个机器翻译的例子,给定一个汉语句子为李明正在家里看电视,可以翻译为Li Ming is watching TV at home、Li Ming at home is watching TV、等等,同样根据语言模型,我们知道前者的概率大于后者,所以翻译成前者比较合理。
目前将预训练的语言模型应用到NLP任务主要有两种策略,一种是基于特征的语言模型,如ELMo,使用将预训练表征作为额外特征的任务专用架构;另一种是基于微调的语言模型,如OpenAI GPT,引入了任务特定最小参数,通过简单地微调预训练参数在下游任务中进行训练。这两类语言模型各有其优缺点,而BERT的出现,似乎融合了它们所有的优点,因此才可以在诸多后续特定任务上取得最优的效果。在这里简单介绍一下ELMo和GPT,具体的可以查看论文等。
Word Embedding
ELMo

ELMo的网络结构采用了双层双向 LSTM,目前语言模型训练的任务目标是根据单词的上下文去正确预测单词,之前的单词序列 Context-before 称为上文,之后的单词序列 Context-after 称为下文。图中左端的前向双层LSTM代表正方向编码器,输入的是从左到右顺序的除了预测单词外的上文 Context-before;右端的逆向双层 LSTM 代表反方向编码器,输入的是从右到左的逆序的句子下文 Context-after;每个编码器的深度都是两层 LSTM 叠加。这个网络结构其实在 NLP 中是很常用的。
但ELMo并不算是真正意义上的结合了上下文信息,而是经过独立训练的从左到右和从右到左LSTM的串联来生成下游任务的特征。(而新提出的BERT中的MLM模型则共同依赖于左右上下文。)
GPT
除了以 ELMO 为代表的这种基于特征融合的预训练方法外,NLP 里还有一种典型做法,这种做法和图像领域的方式就是看上去一致的了,一般将这种方法称为“基于 Fine-tuning 的模式”(基于微调的语言模型),而 GPT(Generative Pre-Training)
就是这一模式的典型开创者。

上图展示了 GPT 的预训练过程,其实和 ELMO 是类似的,主要不同在于两点:
首先,特征抽取器不是用的 RNN,而是用的 Transformer(是个叠加的“自注意力机制(Self Attention)”构成的深度网络,是目前 NLP 里最强的特征提取器)
其次,GPT 的预训练虽然仍然是以语言模型作为目标任务,但是采用的是单向的语言模型,所谓“单向”的含义是指:语言模型训练的任务目标是根据单词的上下文去正确预测单词,之前的单词序列 Context-before 称为上文,之后的单词序列 Context-after 称为下文。ELMO 在做语言模型预训练的时候,预测单词同时使用了上文和下文,而 GPT 则只采用 Context-before 这个单词的上文来进行预测,而抛开了下文。
Transformer
与按顺序读取文本输入的方向模型(从左到右或从右到左)相反,Transformer编码器一次读取整个单词序列。因此它被认为是双向的,尽管说它是非定向的更准确。该特征允许模型基于其所有周围环境(单词的左侧和右侧)来学习单词的上下文。
有两种现有的将预先训练过的语言表示应用于下游任务的策略:基于特征的优化和微调。基于特征的 feature-based (比如 ELMo) and 基于参数微调的 fine-tuning (GPT)
这两种方法在训练前都有相同的目标函数,它们使用单向语言模型来学习通用语言表示。
之后更新……
MLM
现在仔细看一看BERT的两个任务是怎么实现的。
第一个:MLM 遮蔽语言模型(masked language model)
在将单词序列输入BERT之前,每个序列中15%的单词被[MASK]标记替换。然后,该模型基于序列中其他未掩盖的单词提供的上下文,尝试预测被掩盖的单词的原始值。
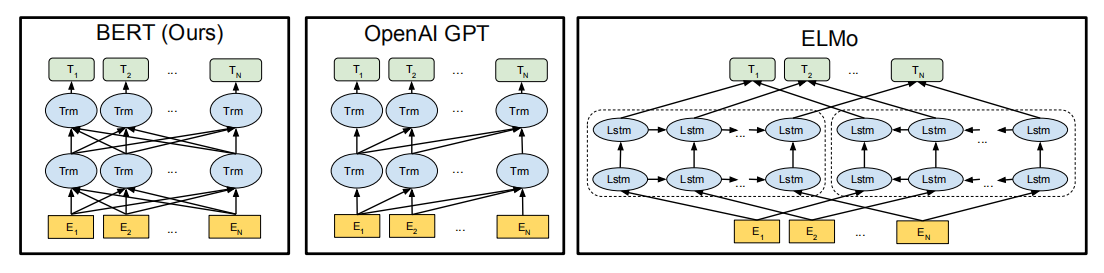
图1:预训练模型架构的差异。BERT使用双向Transformer。OpenAI GPT使用从左到右的Transformer。ELMo使用经过独立训练的从左到右和从右到左LSTM的串联来生成下游任务的特征。三个模型中,只有BERT表示在所有层中共同依赖于左右上下文。
为了达到真正的bidirectional的LM的效果,作者创新性的提出了Masked LM,但是缺点是如果常常把一些词mask起来,未来的fine tuning过程中模型有可能没见过这些词。这个量积累下来还是很大的。因为作者在他的实现中随机选择了句子中15%的WordPiece tokens作为要mask的词。
为了解决这个问题,作者在做mask的时候:
1)80%的时间真的用[MASK]取代被选中的词。比如 my dog is hairy -> my dog is [MASK]
2) 10%的时间用一个随机词取代它:my dog is hairy -> my dog is apple
3) 10%的时间保持不变: my dog is hairy -> my dog is hairy
为什么要以一定的概率保持不变呢? 这是因为刚才说了,如果100%的时间都用[MASK]来取代被选中的词,那么在fine tuning的时候模型会有一些没见过的词。那么为啥要以一定的概率使用随机词呢?这是因为Transformer要保持对每个输入token分布式的表征,否则Transformer很可能会记住这个[MASK]就是”hairy”。至于使用随机词带来的负面影响,文章中说了,所有其他的token(即非”hairy”的token)共享15%*10% = 1.5%的概率,其影响是可以忽略不计的。
NSP 下一句话预测
之所以这么做,应该是考虑到很多 NLP 任务是句子关系判断任务(如问答(QA)和自然语言推理(NLI)都是基于理解两个句子之间的关系)单词预测粒度的训练到不了句子关系这个层级,增加这个任务有助于下游句子关系判断任务。所以可以看到,它的预训练是个多任务过程。这也是 Bert 的一个创新。
在BERT训练过程中,模型接收成对的句子作为输入,并学习预测该对中的第二个句子是否是原始文档中的后续句子。在训练期间,50%的输入是一对,其中第二句是原始文档中的后续句子,而在另外50%中,选择来自语料库的随机句作为第二句。假设随机句子将与第一句断开。
为了帮助模型区分训练中的两个句子,输入在进入模型之前按以下方式处理:
1、在第一个句子的开头插入[CLS]标记,并在每个句子的末尾插入[SEP]标记。
2、将表示句子A或句子B的句子嵌入添加到每个令牌。句子嵌入在概念上类似于2个词的词汇表的标记嵌入。
3、将位置嵌入添加到每个标记以指示其在序列中的位置。位置嵌入的概念和实现在Transformer论文中给出。
要预测第二个句子是否确实与第一个句子连接,执行以下步骤:
1、整个输入序列通过Transformer模型。
2、使用简单的分类层(学习好的重量和偏差矩阵)将[CLS]标记的输出变换为2×1大小的向量。
3、使用softmax计算IsNextSequence的概率。
在训练BERT模型时,Masked LM和Next Sentence Prediction被一起训练,目标是最小化两种策略的组合损失函数。
如何使用BERT(微调)
将BERT用于特定任务相对简单:
BERT可用于各种语言任务,而只需在核心模型中添加一个小层:
1、通过在[CLS]令牌的Transformer输出之上添加分类层,类似于Next Sentence分类,进行情感分析等分类任务。
2、在问题回答任务(例如SQuAD v1.1)中,软件会收到有关文本序列的问题,并且需要在序列中标记答案。使用BERT,可以通过学习标记答案开始和结束的两个额外向量来训练Q&A模型。
3、在命名实体识别(NER)中,软件接收文本序列,并且需要标记出现在文本中的各种类型的实体(人员,组织,日期等)。使用BERT,可以通过将每个令牌的输出向量馈送到预测NER标签的分类层来训练NER模型。
在微调训练中,大多数超参数保持与BERT训练相同,本文给出了需要调整的超参数的具体指导。BERT团队使用这种技术在各种具有挑战性的自然语言任务中获得最先进的结果。
附上BERT在各个项目上的效果:

其他
- 模型尺寸很重要,即使规模很大。BERT_large具有3.45亿个参数,是同类产品中最大的模型。它在小规模任务上显然优于BERT_base,后者使用相同的架构,只有”1.1亿”参数。
- 有足够的训练数据,更多的训练步骤==更高的准确性。例如,在MNLI任务上,训练1M级时,比500 K级获得了近1.0%的额外精度。
- BERT的双向方法(MLM)收敛速度慢于从左到右的方法(因为每批中只预测了15%的单词),但是在少量预训练步骤之后,双向训练仍然优于从左到右的训练。
Softmax函数
Softmax函数,或称归一化指数函数
他把一些输入映射为0-1之间的实数,并且归一化保证和为1,因此多分类的概率之和也刚好为1。
最后的输出是每个分类被取到的概率。