1、编码问题 Bidirectional Encoder Representations from Transformers 只是知道它是利用双向学习 一次读取整个单词序列。不是很明白 transformer的encoder 、decoder
答:可以看一下以下链接:
https://blog.csdn.net/mijiaoxiaosan/article/details/73251443
https://www.codercto.com/a/26520.html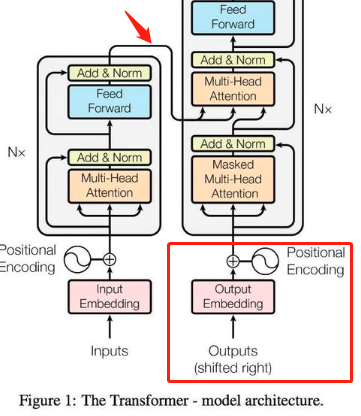
首先了解一下Transformer的作用。Transformer是一个自编码器,由encoder和decoder组成,可以用来做机器翻译。这个图是《attention is all you need》里面的图,图中的模型在机器翻译任务中应该是这样工作的。假设是将“我爱中国”翻译成“l love china”,那么encoder这里的input应该就是“我爱中国”,decoder这里的output应该是“l love china”。模型首先通过encoder将“我爱中国”编码成特征A,decoder结合输入“l love china”,将特征A解码为概率分布B。我理解的机器翻译的任务大概是这么训练的。
Encoder的作用主要是得到从中文句子中得到特征A,方法就是通过N层的 “由多头自注意力网络和前馈神经网络组成的”网络(图1红框)来提取特征。红框的网络下面部分是多头自注意力网络(图2),“多头”的意思是将一个大的向量划分成h个小的向量来计算(因为这样效果更好,我也不知道为啥会更好),“自注意力”是指将同一个向量作为V、K、Q的值输入。
Decoder作用主要是根据encoder得到地特征A,结合输入的output embadding来得到分布B。它的网络是图1的蓝色框,由两层多头注意力网络和一层前馈神经网络组成。最下面那层多头注意力网络的输入是output embadding,上面那层的Q,K的输入是encoder得到的特征A,输入V是下面那层注意力网络的输出。
Transformer在BERT中的应用时input 和output是一样的,输出的时候不用去计算分布,只需要得到最后一个网络的结果就行,图一绿色箭头部分。
附上transform学习:
https://baijiahao.baidu.com/s?id=1614828439463695390&wfr=spider&for=pc
需要注意的是:BERT并不完全是Decoder and encoder , 实际上只有编码器encoder (这是一个新问题……待解决)
2、ELMo和MLM的理解
ELMo也是双向的 但是是对 两个方向的 一个线性组合 那么MLM和他最大的区别是将两个方向的信息同时利用而不是分别提取后再组合,这样理解对吗?
参考词向量技术:https://www.jianshu.com/p/a6bc14323d77
答:
ELMo是从左到右的LSTM和从右到左的LSTM网络训练得到的embadding拼接起来作为下游任务的输入,以这样的方法来得到单词的上下文信息。个人感觉这样做的话,确实是利用了上下文信息,但是感觉用的有点生硬。
MLM任务:随机遮住15%的单词,预测这些单词,相当于做完形填空。我认为这样做能够更准确地涵盖上下文的意思。所以在BERT这篇文章里面将MLM这样的embadding方式称为深层双向的模型。
3、mask一部分,因为在其他任务中不能mask掉这些词,所以采用了80%加mask 10%用随机词替换 10%保留原词 要msak的那个位置是定好了的吗 整个这个过程不太清楚?怎么计算预测的准确性呢?

答:
文中的解释:Mask的位置是随机的。即对于一段文字,随机mask其中15%的词,由于encoder在处理的时候,不知道哪些词是被遮住了,所以它会被迫保持每一个单词的上下文表示。
MLM任务是随机遮住单词,然后通过学习来预测它本身,相当于完形填空。为了预测mask这个词,encoder会对关注mask这个词的上下文。由于一开始输入的时候,我们是随机mask单词的,encoder不知道哪些单词被mask了,所以他会对每个单词的上下文都关注。(这个关注是什么呢?)
对上下文的关注是指,对这个词进行embadding时,包含了上下文的信息
Transformer编码器不知道它将被要求预测哪些单词,或者哪些已经被随机单词替换,因此它必须对每个输入词保持分布式的上下文表示???
怎么计算预测的准确性:
将预测的词语原来的词相比较。
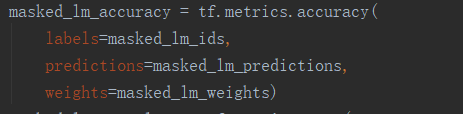
可以理解为:在随机选择mask的时候原来的词是会被记录的,然后与预测出来的词做比较吗?(可以,看源代码就知道了)
4、MLM算是无监督吗 ,预测下一句NSP 有标注lable,那它就是监督学习?
答:
我觉得MLM是有监督的,label就是被遮住的那个词。这一点我之前也没有想过,我是在上一题中看了代码才这样认为的。
NSP是有监督的。(有点疑问……)
5、在训练BERT模型时,Masked LM和Next Sentence Prediction被一起训练,目标是最小化两种策略的组合损失函数。没懂?
答:
我的理解:训练bert模型的过程主要就是将输入的embaddings Ei经过一系列操作变成输出的Ti。如下图:

这个图的是对 一对句子进行分类,(NSP)其实也是这样的任务。对于这样的任务,主要就是对calss label进行分类。对于MLM任务,其实就是在最后一层对被mask的T(红框框里的词)进行预测。所以说这两个任务是同时进行的。
对“目标是最小化两种策略的组合损失函数”的理解,可以看代码:
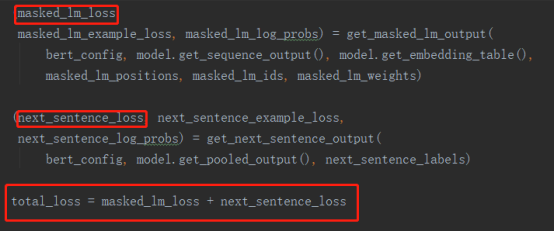
可以看出,其实最终的loss就是两个子任务的loss的和。
6、输入都是一个个的token 但论文中是英文的,如果是中文的词 在数据清洗之后或者去掉一些停用词之类的 会不会有什么影响呢?

这个图没太明白……目前的理解是:第一层是对于token 的编码 第二层是对不同语句的编码 第三层是对每个token位置的一个编码 但是这三个编码具体怎么利用的呢?
答:
关于处理中文是,在去掉停用词之后,会不会对BERT模型有影响。猜想一下,如果这些操作没有改变语义的话,应该是没有影响的。关于处理汉语的BERT模型,官方在github上面以及给出训练好的模型,如果需要的话可以去下载。
https://github.com/google-research/bert
对于句子中的每一个词,例如my这个单词,BERT模型是将token embadding、segment embadding、position embadding这三个向量相加之后得到的向量作为最终的输入embadding。
7、没太懂这个收敛是什么意思 ?
答:
因为BERT模型在每一次训练过程中只对当前batch中的15%的词进行预测(因为每次随机遮住15%的词),而LTR模型在训练的时候每一次都会对每一次进行训练。所以用MLM的话,收敛速度会比LTR慢。直观上也可以理解,假设一个sequence有100个token,那么在BERT模型的MLM任务中,每次只有随机15个单词被预测,所以需要多训练几次,这儿样随机到的词就更多,更有利于上下文的表达。另外预测这15个词的过程也会有时间上的开销,所以收敛会慢一点。
BERT损失函数仅考虑掩盖值的预测并忽略非掩盖字的预测。因此,模型比定向模型收敛得慢
8、模型具体的参数设置还是不太明白。fine-tuning微调?
答:
BERT BASE: L = 12,H = 768,A = 12
L:Num of layers,下图中红色部分,含义是encoder和decoder的各自网络层数
H: Hidden size,蓝色部分,隐藏层
A: Num of Heads,绿色部分,多头注意力机制中头的部分
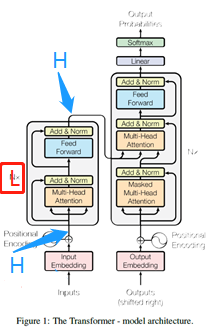
在微调过程中,参数要加载预训练时候的参数:

附上模型参数解释:
Args:
vocab_size: 输入BERT模型的词汇大小
hidden_size: 编码器层和较小层的大小
num_hidden_layers: Number of hidden layers in the Transformer encoder.
num_attention_heads: Number of attention heads for each attention layer in
the Transformer encoder.
intermediate_size: The size of the "intermediate" (i.e., feed-forward)
layer in the Transformer encoder.
hidden_act: The non-linear activation function (function or string) in the
encoder and pooler.
hidden_dropout_prob: The dropout probability for all fully connected
layers in the embeddings, encoder, and pooler.
attention_probs_dropout_prob: The dropout ratio for the attention
probabilities.
max_position_embeddings: The maximum sequence length that this model might
ever be used with. Typically set this to something large just in case
(e.g., 512 or 1024 or 2048).
type_vocab_size: The vocabulary size of the `token_type_ids` passed into
`BertModel`.
initializer_range: The stdev of the truncated_normal_initializer for
initializing all weight matrices.
"""
如果要跑BERT的示例程序,那么执行命令中需要注意调一下以下参数:

这几个主要是对于建立在BERT预训练之后的网络
数据集:GULE
PS:解答来自某位师兄and网上,仅供参考!
待完善…………