双链表
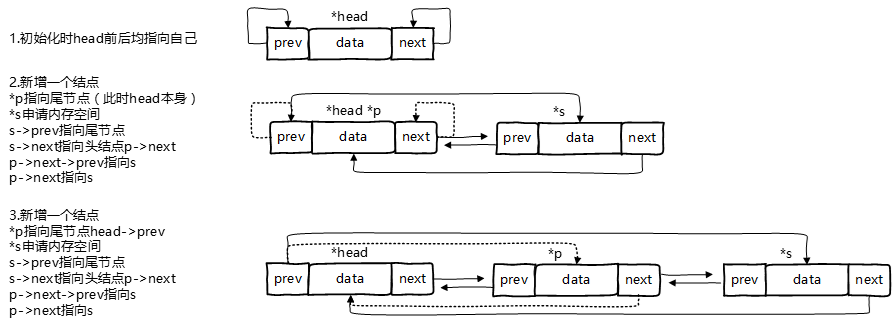
双向链表也叫双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。一般我们都构造双向循环链表,其中的结点如下:

其中,Data为结点存储的数据元素,prev指针指向该结点的前驱结点,next指针指向该结点的后继结点。双向链表通常含有一个表头结点,亦称哨兵结点(Sentinel Node),用于简化插入和删除等操作。带头结点的非空双向链表如下图所示:

接下来看一下链表的构造及其使用方法:
双向链表的构造
1
2
3
4
5
6typedef struct Node pNode;
typedef struct Node
{
int data;
struct Node *prior, *next;
} Node;初始化双向循环链表(head的头尾均指向本身)
1 | void InitList(pNode **head) |
- 查找操作:
在带表头的双向链表中查找数据域为一特定值的某个结点时,可从表头结点开始向后依次匹配各结点数据域的值,若与特定值相同则返回指向该结点的指针,否则继续往后遍历直至表尾。
- 前插操作:
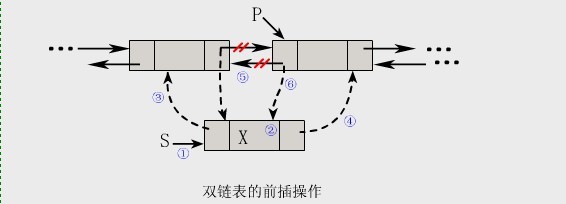
1 | void DInsertBefore(pNode *p,typedef x) |
- 删除操作:
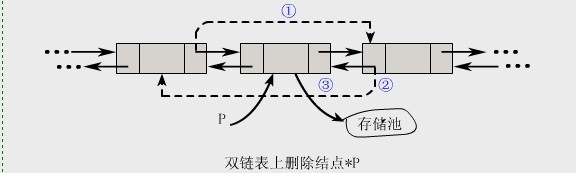
1 | void DDeleteNode(DListNode *p) |
注意:在双链表中插入和删除必须同时修改两个方向上的指针!
循环链表
双向链表通常采用带表头结点的循环链表形式,即双向循环链表。双向循环链表在双向链表的基础上,将表头结点的前驱指针指向尾结点,尾结点的后驱指针指向头结点,首尾相连形成一个双向环。